Deep ensemble for ENSO-forecasting¶
In this tutorial you learn how to use a neural network model called Deep Ensemble (DE) for the ENSO forecasting. This network architecture was initially developed Lakshminarayanan et al. (2017).
DEs are feed foreword neural networks that predict the mean and the standard deviation of a Gaussian. Hence, their predicion comes with an uncertainty estimation which is a valuable feature for ENSO-forecasting.
Create a data pipe line¶
At first, we define a data pipeline. This is in general quite useful to keep your code clean and also to reuse the pipeline for later purpose.
The data pipeline generates returns:
The feature array
The label array
The time array corresponding to the time of the label
NOTE (again): Lead time is defined as the time that passed between the last observed and the first date of the target season. Hence, negative appear, e.g. if you compare the DJF season with the target season JFM, you have a lead time of -2 month (Last observed date: Feburary 28/29, First date of the target season January 1).
[15]:
import numpy as np
from sklearn.preprocessing import StandardScaler
from ninolearn.utils import include_time_lag
from ninolearn.IO.read_processed import data_reader
def pipeline(lead_time):
"""
Data pipeline for the processing of the data before the Deep Ensemble
is trained.
:type lead_time: int
:param lead_time: The lead time in month.
:returns: The feature "X" (at observation time), the label "y" (at lead
time), the target season "timey" (least month)
"""
reader = data_reader(startdate='1980-01', enddate='2018-12')
# indeces
oni = reader.read_csv('oni')
iod = reader.read_csv('iod')
wwv = reader.read_csv('wwv')
# seasonal cycle
sc = np.cos(np.arange(len(oni))/12*2*np.pi)
# network metrics
network_ssh = reader.read_statistic('network_metrics', variable='sst', dataset='ERSSTv5', processed="anom")
c2 = network_ssh['fraction_clusters_size_2']
H = network_ssh['corrected_hamming_distance']
# time lag
time_lag = 12
# shift such that lead time corresponds to the definition of lead time
shift = 3
# process features
feature_unscaled = np.stack((oni, sc, wwv, iod,
c2, H), axis=1)
# scale each feature
scalerX = StandardScaler()
Xorg = scalerX.fit_transform(feature_unscaled)
# set nans to 0.
Xorg = np.nan_to_num(Xorg)
# arange the feature array
X = Xorg[:-lead_time-shift,:]
X = include_time_lag(X, max_lag=time_lag)
# arange label
yorg = oni.values
y = yorg[lead_time + time_lag + shift:]
# get the time axis of the label
timey = oni.index[lead_time + time_lag + shift:]
return X, y, timey
Split the data set¶
For the training and testing of machine learning models it is crucial to split the data set into:
Train data set which is used to train the weights of the neural network
Validation data set which is used to check for overfitting (e.g. when using early stopping) and to optimize the hyperparameters
Test data set which is used to to evaluate the trained model.
NOTE: It is important to understand that hyperparamters must be tuned so that the result is best for the Validation data set and not for the test data set. Otherwise you can not rule out the case that the specific hyperparameter setting just works good for the specific test data set but is not generally a good hyperparameter setting.
In the following cell the train and the validation data set are still one data set, because this array will be later splitted into two arrays when th model is fitted.
[16]:
import keras.backend as K
from ninolearn.learn.models.dem import DEM
# clear memory from previous sessions
K.clear_session()
# define the lead time
lead_time = 3
# get the features (X), the label (y) and
# the time axis of the label (timey)
X, y, timey = pipeline(lead_time)
# split the data set into
test_indeces = (timey>='2001-01-01') & (timey<='2018-12-01')
train_val_indeces = np.invert(test_indeces)
train_val_X, train_val_y, train_val_timey = X[train_val_indeces,:], y[train_val_indeces], timey[train_val_indeces]
testX, testy, testtimey = X[test_indeces,:], y[test_indeces], timey[test_indeces]
Fit the model¶
Now it is time to train the model! For this a random search is used for all keyword arguments that are passed in a list to the DEM.set_parameters() method.
[17]:
# initiated an instance of the DEM (Deep Ensemble Model) class
model = DEM()
# Set parameters
model.set_hyperparameters(layers=1, neurons=16, dropout=[0.1, 0.5], noise_in=[0.1,0.5], noise_sigma=[0.1,0.5],
noise_mu=[0.1,0.5], l1_hidden=[0.0, 0.2], l2_hidden=[0., 0.2],
l1_mu=[0.0, 0.2], l2_mu=[0.0, 0.2], l1_sigma=[0.0, 0.2],
l2_sigma=[0.0, 0.2], lr=[0.0001,0.01], batch_size=100, epochs=500, n_segments=5,
n_members_segment=1, patience=30, verbose=0, pdf='normal')
# Use a random search to find the optimal hyperparamteres
model.fit_RandomizedSearch(train_val_X, train_val_y, n_iter=20)
Search iteration Nr 1/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00052: early stopping
46/46 [==============================] - 0s 84us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00132: early stopping
46/46 [==============================] - 0s 71us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00059: early stopping
46/46 [==============================] - 0s 50us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 50us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00096: early stopping
46/46 [==============================] - 0s 46us/step
Loss: 0.3823194860116296
Computation time: 8.8s
New best hyperparameters
Mean loss: 0.3823194860116296
{'layers': 1, 'neurons': 16, 'dropout': 0.41903529337320344, 'noise_in': 0.10347229433415084, 'noise_sigma': 0.2047585880842553, 'noise_mu': 0.49594753897933586, 'l1_hidden': 0.13152395470050957, 'l2_hidden': 0.08330581312568477, 'l1_mu': 0.15149749010743152, 'l2_mu': 0.11593669948708028, 'l1_sigma': 0.09967560356729449, 'l2_sigma': 0.1244877471669649, 'lr': 0.004634984622626636, 'batch_size': 100, 'epochs': 500, 'n_segments': 5, 'n_members_segment': 1, 'patience': 30, 'verbose': 0, 'pdf': 'normal', 'n_members': 5}
Search iteration Nr 2/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00119: early stopping
46/46 [==============================] - 0s 77us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00071: early stopping
46/46 [==============================] - 0s 44us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00044: early stopping
46/46 [==============================] - 0s 46us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 91us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00040: early stopping
46/46 [==============================] - 0s 50us/step
Loss: 0.536129170332266
Computation time: 8.8s
Search iteration Nr 3/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00054: early stopping
46/46 [==============================] - 0s 73us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00060: early stopping
46/46 [==============================] - 0s 51us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00041: early stopping
46/46 [==============================] - 0s 46us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 51us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00150: early stopping
46/46 [==============================] - 0s 83us/step
Loss: 0.35812768055045086
Computation time: 9.1s
New best hyperparameters
Mean loss: 0.35812768055045086
{'layers': 1, 'neurons': 16, 'dropout': 0.4969969924220081, 'noise_in': 0.19616484546423987, 'noise_sigma': 0.19645462330381283, 'noise_mu': 0.3658885794233012, 'l1_hidden': 0.18712187452622892, 'l2_hidden': 0.06757120513272023, 'l1_mu': 0.030331377920337535, 'l2_mu': 0.053227700652674396, 'l1_sigma': 0.02411236317733605, 'l2_sigma': 0.040351529483836225, 'lr': 0.005768259463912277, 'batch_size': 100, 'epochs': 500, 'n_segments': 5, 'n_members_segment': 1, 'patience': 30, 'verbose': 0, 'pdf': 'normal', 'n_members': 5}
Search iteration Nr 4/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00046: early stopping
46/46 [==============================] - 0s 65us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 60us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00036: early stopping
46/46 [==============================] - 0s 70us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00057: early stopping
46/46 [==============================] - 0s 48us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00047: early stopping
46/46 [==============================] - 0s 55us/step
Loss: 0.3036035604774952
Computation time: 8.5s
New best hyperparameters
Mean loss: 0.3036035604774952
{'layers': 1, 'neurons': 16, 'dropout': 0.23004481921165137, 'noise_in': 0.46270830851367095, 'noise_sigma': 0.45638086691256086, 'noise_mu': 0.2680286780681471, 'l1_hidden': 0.07392628874726237, 'l2_hidden': 0.18280564143180358, 'l1_mu': 0.03358655835944029, 'l2_mu': 0.04964944019738571, 'l1_sigma': 0.1284721092428513, 'l2_sigma': 0.06915923429350067, 'lr': 0.007624401534440948, 'batch_size': 100, 'epochs': 500, 'n_segments': 5, 'n_members_segment': 1, 'patience': 30, 'verbose': 0, 'pdf': 'normal', 'n_members': 5}
Search iteration Nr 5/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00081: early stopping
46/46 [==============================] - 0s 75us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00104: early stopping
46/46 [==============================] - 0s 48us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00065: early stopping
46/46 [==============================] - 0s 53us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 109us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00092: early stopping
46/46 [==============================] - 0s 53us/step
Loss: 0.46464331263433334
Computation time: 11.1s
Search iteration Nr 6/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00067: early stopping
46/46 [==============================] - 0s 48us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00202: early stopping
46/46 [==============================] - 0s 48us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00058: early stopping
46/46 [==============================] - 0s 78us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 76us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00145: early stopping
46/46 [==============================] - 0s 54us/step
Loss: 0.38047359326611396
Computation time: 10.3s
Search iteration Nr 7/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00044: early stopping
46/46 [==============================] - 0s 52us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00048: early stopping
46/46 [==============================] - 0s 49us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 109us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 68us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 46us/step
Loss: 0.5316211005915765
Computation time: 9.0s
Search iteration Nr 8/20
Train member Nr 1/5
--------------------------------------
46/46 [==============================] - 0s 71us/step
Train member Nr 2/5
--------------------------------------
46/46 [==============================] - 0s 72us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 81us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 85us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 52us/step
Loss: 0.5255566728503809
Computation time: 12.6s
Search iteration Nr 9/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00081: early stopping
46/46 [==============================] - 0s 76us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00083: early stopping
46/46 [==============================] - 0s 54us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00044: early stopping
46/46 [==============================] - 0s 51us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 74us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00081: early stopping
46/46 [==============================] - 0s 82us/step
Loss: 0.27809078570293344
Computation time: 9.2s
New best hyperparameters
Mean loss: 0.27809078570293344
{'layers': 1, 'neurons': 16, 'dropout': 0.39958636593035646, 'noise_in': 0.2801139377909808, 'noise_sigma': 0.23157012188768117, 'noise_mu': 0.35653555105103407, 'l1_hidden': 0.09710335042994389, 'l2_hidden': 0.030661447903490638, 'l1_mu': 0.15575931599607082, 'l2_mu': 0.11771970888833305, 'l1_sigma': 0.1712642514949432, 'l2_sigma': 0.06606412633278731, 'lr': 0.0053689200750857225, 'batch_size': 100, 'epochs': 500, 'n_segments': 5, 'n_members_segment': 1, 'patience': 30, 'verbose': 0, 'pdf': 'normal', 'n_members': 5}
Search iteration Nr 10/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00135: early stopping
46/46 [==============================] - 0s 78us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00111: early stopping
46/46 [==============================] - 0s 39us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00105: early stopping
46/46 [==============================] - 0s 62us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 80us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00077: early stopping
46/46 [==============================] - 0s 47us/step
Loss: 0.22250935001217803
Computation time: 11.0s
New best hyperparameters
Mean loss: 0.22250935001217803
{'layers': 1, 'neurons': 16, 'dropout': 0.17954696328551784, 'noise_in': 0.48765233117205986, 'noise_sigma': 0.2344138299710665, 'noise_mu': 0.28641868136528587, 'l1_hidden': 0.07373889141305061, 'l2_hidden': 0.06504845804389796, 'l1_mu': 0.07739008026671873, 'l2_mu': 0.05793634510447043, 'l1_sigma': 0.07610942970011525, 'l2_sigma': 0.13103696054979164, 'lr': 0.004272988853087075, 'batch_size': 100, 'epochs': 500, 'n_segments': 5, 'n_members_segment': 1, 'patience': 30, 'verbose': 0, 'pdf': 'normal', 'n_members': 5}
Search iteration Nr 11/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00053: early stopping
46/46 [==============================] - 0s 71us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00047: early stopping
46/46 [==============================] - 0s 49us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00039: early stopping
46/46 [==============================] - 0s 54us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 118us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00071: early stopping
46/46 [==============================] - 0s 68us/step
Loss: 0.35565991032382716
Computation time: 10.1s
Search iteration Nr 12/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00082: early stopping
46/46 [==============================] - 0s 82us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00077: early stopping
46/46 [==============================] - 0s 70us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00034: early stopping
46/46 [==============================] - 0s 104us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 55us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00121: early stopping
46/46 [==============================] - 0s 53us/step
Loss: 0.25811459438308426
Computation time: 10.8s
Search iteration Nr 13/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00115: early stopping
46/46 [==============================] - 0s 61us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00040: early stopping
46/46 [==============================] - 0s 75us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00042: early stopping
46/46 [==============================] - 0s 49us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00122: early stopping
46/46 [==============================] - 0s 49us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00042: early stopping
46/46 [==============================] - 0s 66us/step
Loss: 0.29950643440951474
Computation time: 9.8s
Search iteration Nr 14/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00107: early stopping
46/46 [==============================] - 0s 96us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 54us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00058: early stopping
46/46 [==============================] - 0s 168us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 73us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00032: early stopping
46/46 [==============================] - 0s 123us/step
Loss: 0.5440963976409124
Computation time: 15.5s
Search iteration Nr 15/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00032: early stopping
46/46 [==============================] - 0s 152us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00040: early stopping
46/46 [==============================] - 0s 150us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00054: early stopping
46/46 [==============================] - 0s 103us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00041: early stopping
46/46 [==============================] - 0s 133us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00059: early stopping
46/46 [==============================] - 0s 150us/step
Loss: 0.28715189351983694
Computation time: 20.9s
Search iteration Nr 16/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00095: early stopping
46/46 [==============================] - 0s 193us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00033: early stopping
46/46 [==============================] - 0s 59us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00105: early stopping
46/46 [==============================] - 0s 146us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00034: early stopping
46/46 [==============================] - 0s 82us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00045: early stopping
46/46 [==============================] - 0s 95us/step
Loss: 0.513937189883512
Computation time: 21.3s
Search iteration Nr 17/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00112: early stopping
46/46 [==============================] - 0s 156us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00088: early stopping
46/46 [==============================] - 0s 67us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 152us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 89us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00181: early stopping
46/46 [==============================] - 0s 127us/step
Loss: 0.3518007106755091
Computation time: 21.9s
Search iteration Nr 18/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00105: early stopping
46/46 [==============================] - 0s 126us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00128: early stopping
46/46 [==============================] - 0s 66us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00033: early stopping
46/46 [==============================] - 0s 67us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 155us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00061: early stopping
46/46 [==============================] - 0s 105us/step
Loss: 0.38344535646231276
Computation time: 22.7s
Search iteration Nr 19/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00079: early stopping
46/46 [==============================] - 0s 286us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00073: early stopping
46/46 [==============================] - 0s 169us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00041: early stopping
46/46 [==============================] - 0s 106us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00033: early stopping
46/46 [==============================] - 0s 67us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00057: early stopping
46/46 [==============================] - 0s 82us/step
Loss: 0.32215388132178263
Computation time: 20.3s
Search iteration Nr 20/20
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00065: early stopping
46/46 [==============================] - 0s 136us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00084: early stopping
46/46 [==============================] - 0s 96us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00032: early stopping
46/46 [==============================] - 0s 60us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 246us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00047: early stopping
46/46 [==============================] - 0s 132us/step
Loss: 0.4694813759430595
Computation time: 20.6s
Refit the model with best hyperparamters
{'layers': 1, 'neurons': 16, 'dropout': 0.17954696328551784, 'noise_in': 0.48765233117205986, 'noise_sigma': 0.2344138299710665, 'noise_mu': 0.28641868136528587, 'l1_hidden': 0.07373889141305061, 'l2_hidden': 0.06504845804389796, 'l1_mu': 0.07739008026671873, 'l2_mu': 0.05793634510447043, 'l1_sigma': 0.07610942970011525, 'l2_sigma': 0.13103696054979164, 'lr': 0.004272988853087075, 'batch_size': 100, 'epochs': 500, 'n_segments': 5, 'n_members_segment': 1, 'patience': 30, 'verbose': 0, 'pdf': 'normal', 'n_members': 5}
Train member Nr 1/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00067: early stopping
46/46 [==============================] - 0s 71us/step
Train member Nr 2/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00160: early stopping
46/46 [==============================] - 0s 306us/step
Train member Nr 3/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00061: early stopping
46/46 [==============================] - 0s 276us/step
Train member Nr 4/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00031: early stopping
46/46 [==============================] - 0s 191us/step
Train member Nr 5/5
--------------------------------------
Restoring model weights from the end of the best epoch
Epoch 00047: early stopping
46/46 [==============================] - 0s 178us/step
Loss: 0.3001609052652898
Computation time: 21.4s
best loss search: 0.22250935001217803
loss refitting : 0.3001609052652898
Make predictions for the test data set¶
Now we can use the trained models to make predicitons on the test data set to evaluate how good the model perfoms on a data set that it never saw before.
[18]:
pred_mean, pred_std = model.predict(testX)
Plot the prediction¶
Let’s see how the predicion is looking like
[20]:
import matplotlib.pyplot as plt
from ninolearn.plot.prediction import plot_prediction
import pandas as pd
plt.subplots(figsize=(15,3.5))
plt.axhspan(-0.5,
-6,
facecolor='blue',
alpha=0.1,zorder=0)
plt.axhspan(0.5,
6,
facecolor='red',
alpha=0.1,zorder=0)
plt.xlim(testtimey[0], testtimey[-1])
plt.ylim(-3,3)
# plot the prediction
plot_prediction(testtimey, pred_mean, std=pred_std, facecolor='royalblue', line_color='navy')
# plot the observation
plt.plot(timey, y, "k")
plt.show()
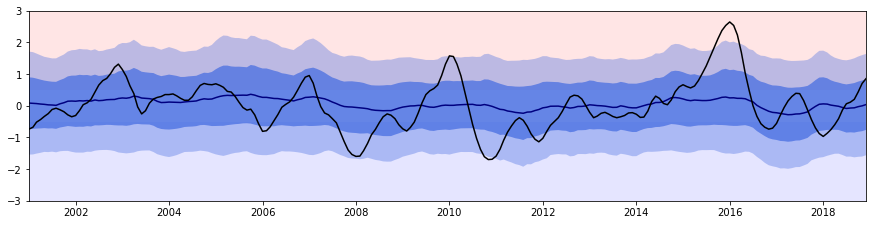
Evaluate the model¶
We can evaluate the model a bit more quantitatively using the loss function that was used to train the model, namely the negative-log-likelihood of the Gaussian and the correlation between the predicted mean and the observed ONI index.
[21]:
from ninolearn.plot.evaluation import plot_correlation
loss = model.evaluate(testy, pred_mean, pred_std)
print(f"Loss (Negative-Log-Likelihood): {loss}")
# make a plot of the seasonal correaltion
# note: - pd.tseries.offsets.MonthBegin(1) appears to ensure that the correlations are plotted
# agains the correct season
plot_correlation(testy, pred_mean, testtimey - pd.tseries.offsets.MonthBegin(1), title="")
Loss (Negative-Log-Likelihood): 0.19635278216131088
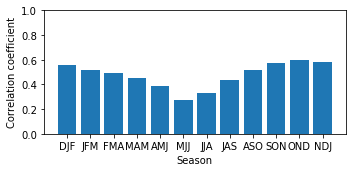
[ ]: